
Cuda vs oneAPI – Performance in HPC Applications
As the world becomes increasingly complex, so do the challenges we face in fields ranging from science to finance. High-performance computing (HPC) has become the go-to solution for tackling these complex problems, which means the load is distributed over CPU, GPU and FPGAs, reducing excessive load on one component. To meet the ever-growing demands of HPC, developers are turning to cutting-edge technologies such as heterogeneous computing, oneAPI, and CUDA.
So what exactly are these technologies, and how can they help us achieve even greater computing power? In this blog, we’ll take a deep dive into the world of HPC applications, exploring the latest developments in CUDA and oneAPI, and how they can be leveraged to write high-performance code for CPUs, GPUs, and FPGAs. Whether you’re a developer, a scientist, or just someone interested in the cutting edge of technology, this blog is sure to provide some valuable insights into the world of HPC.
Table of Contents
What is CUDA and oneAPI?
CUDA is a parallel computing platform developed by NVIDIA, that enables programmers to write highly parallel programs that can run blazingly fast on NVIDIA GPUs, thereby achieving massive acceleration of compute-intensive applications. On the other hand, oneAPI is a unified programming model developed by Intel that aims to provide a single, standards-based programming interface that can be used to write high-performance code for different architectures such as CPUs, GPUs, and FPGAs.
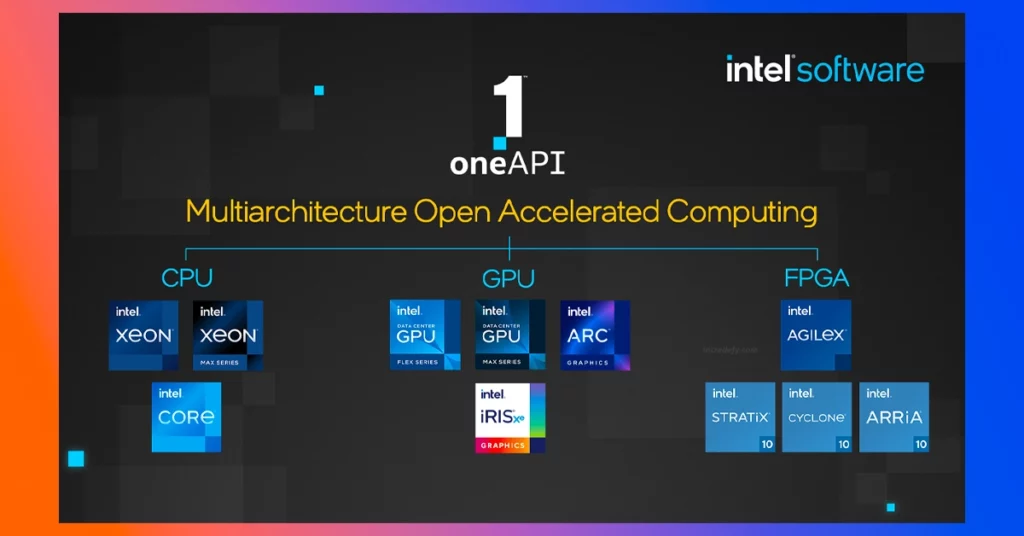
Performance and Scalabilty Comparison: CUDA vs oneAPI
A research study titled “Comparing CUDA and oneAPI for HPC Applications: An Empirical Study” was conducted by Xing Liu, Luanzheng Guo, and Xian-He Sun, which evaluated the performance and scalability of the two technologies on a variety of HPC benchmarks.
The study found that CUDA is generally more efficient than oneAPI in terms of raw performance. This is due to the fact that CUDA is specifically designed to work with NVIDIA GPUs and can take full advantage of the unique features and capabilities of these devices.
Portability Comparison: CUDA vs oneAPI
However, the study also found that oneAPI provides better portability across different architectures, as it is designed to work with a wide range of hardware, including CPUs, GPUs, and FPGAs. This makes it a more flexible option for developers who need to target multiple platforms.
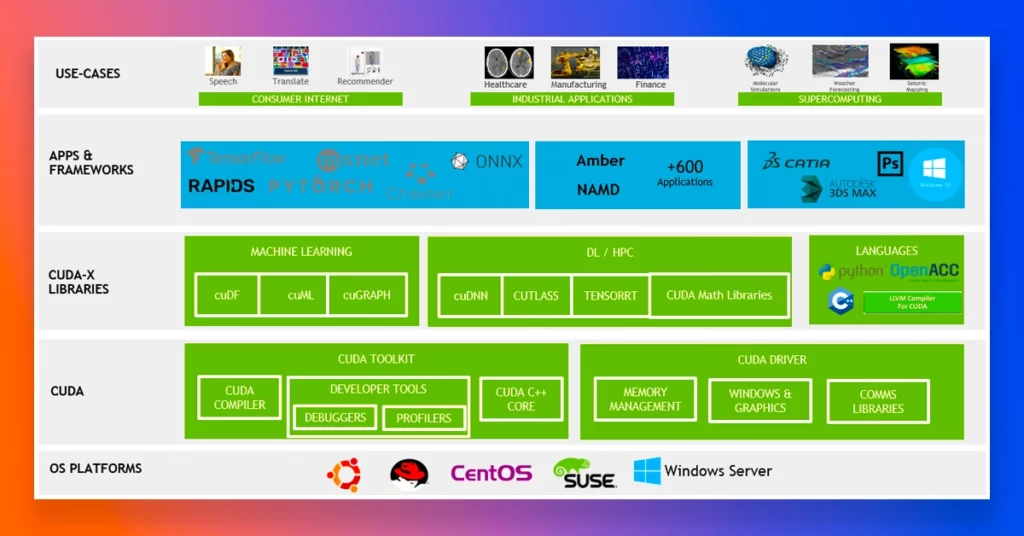
The Importance of Application-Specific Benchmarking
Another key finding of the study was that the performance of both CUDA and oneAPI can be highly dependent on the specific application being run. In some cases, oneAPI was able to achieve better performance than CUDA, particularly in cases where the application was heavily reliant on memory access rather than computation. This highlights the importance of careful benchmarking and testing when choosing between the two technologies.
Migrating CUDA Code to oneAPI using the dpct Tool
oneAPI is an industry proposal that includes a set of open specifications, the DPC++ language, and domain libraries, providing different hardware vendors with their own compatible implementations. A research paper titled “Early Experiences Migrating CUDA codes to oneAPI,” discusses the challenges of programming for different hardware devices and introduces Intel’s oneAPI programming environment, which allows code to be run on various devices. The article also presents the experiences of porting two CUDA applications to DPC++ using the dpct tool. Although dpct does not achieve 100% of the migration task, it performs most of the work and reports pending adaptations to the programmer.
Intel oneAPI implementation comprises the Intel DPC++ compiler, dpct tool, and optimized libraries. To migrate CUDA codes to DPC++, developers can use the dpct tool, which generates human-readable code and inline comments to help developers finish migrating the application. In this work, the Matrix Multiplication (MM) and Reduction (RED) CUDA codes were translated to DPC++ using the dpct tool.
Migrating Matrix Multiplication (MM) CUDA Code to oneAPI
The dpct tool assists in porting CUDA code to DPC++, and typically migrates 80-90% of the code in an automatic manner. However, the resulting code becomes much more complex and longer than the original CUDA code. The migrated DPC++ code is longer because dpct adds comments to inform the programmer about possible issues, and the code is more complex because it is the result of an automatic translation. The tool correctly translates the local memory usage and the synchronization barriers, and the kernel bodies are very similar codes.
Migrating Reduction (RED) CUDA Code to oneAPI
In the case of RED, dpct is not able to translate advanced functionalities such as CUDA Cooperative Groups. Although the tool manages to translate most of the original CUDA code, it inserts comments to inform the programmer about the issue. It also presents the comment inserted by dpct to inform the programmer about this limitation.
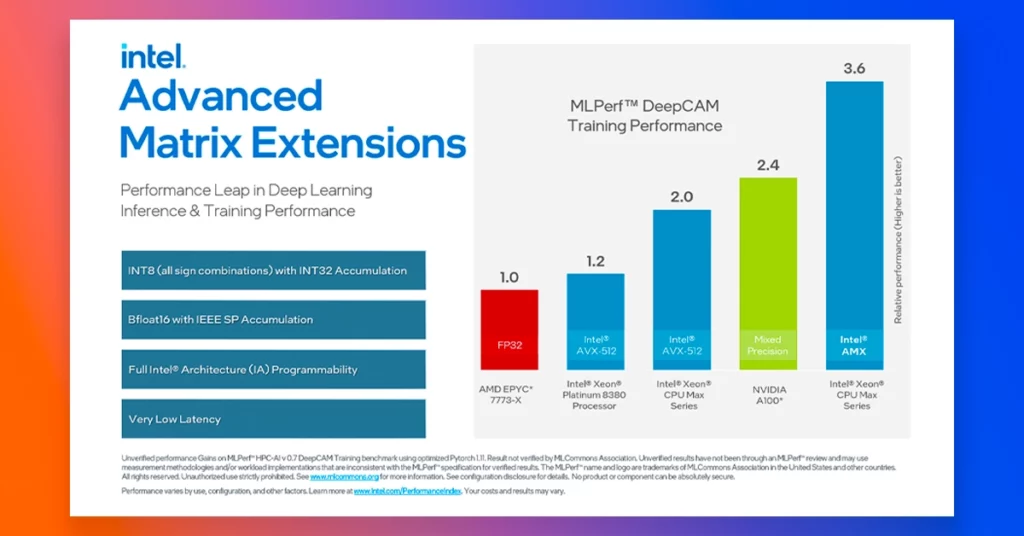
Experimental Results – Cuda vs oneAPI
The experimental work was carried out on two hardware platforms, an Intel Core i3-4160 3.60GHz processor with a NVIDIA GeForce RTX 2070 GPU and an Intel Core i9-10920X 3.50GHz processor with an Intel Iris Xe MAX Graphics GPU. Different workloads were configured for MM. The execution times of MM (CUDA and DPC++ versions) on different experimental platforms. The DPC++ code presents some overhead compared to the original code on the RTX 2070, but it is important to note that the oneAPI support for NVIDIA GPUs is still experimental. The DPC++ code was successfully executed on all selected platforms and the results were correct in all cases, verifying its functional portability.
Conclusion: The Future of Computing with CUDA and oneAPI
In conclusion, both CUDA and oneAPI are powerful tools for high-performance computing, and each has its own strengths and weaknesses. As the field of computer science continues to evolve, it is likely that both technologies will continue to play an important role in enabling faster and more efficient computation. It will be interesting to see how these two technologies and others like them continue to evolve in the coming years and how they will impact the future of computing. Here is our detailed guide to oneAPI.
FAQs
What is CUDA?
CUDA is a parallel computing platform developed by NVIDIA, that enables programmers to write highly parallel programs that can run on NVIDIA GPUs for massive acceleration of compute-intensive applications.
What is oneAPI?
oneAPI is a unified programming model developed by Intel that aims to provide a single, standards-based programming interface that can be used to write high-performance code for different architectures such as CPUs, GPUs, and FPGAs.
Which technology is more efficient in terms of raw performance, CUDA vs oneAPI?
CUDA is generally more efficient than oneAPI in terms of raw performance, due to its specific design to work with NVIDIA GPUs and take full advantage of their unique features and capabilities.
Can CUDA code be migrated to oneAPI?
Yes, the dpct tool from Intel oneAPI programming environment can be used to migrate CUDA code to oneAPI, although some adaptations may be required to ensure full compatibility.
What is the future of computing with CUDA and oneAPI?
Both CUDA and oneAPI are powerful tools for high-performance computing, and each has its own strengths and weaknesses. As the field of computer science continues to evolve, it is likely that both technologies will continue to play an important role in enabling faster and more efficient computation.
CUDA vs oneAPI: Which technology, provides better portability across different architectures?
oneAPI provides better portability across different architectures as it is designed to work with a wide range of hardware, including CPUs, GPUs, and FPGAs.


